Sure-footed refactoring
About two years ago I read a post on the Github engineering blog written by Jesse Toth. She described an approach taken at Github when they needed to tackle a refactor of some complex permissions code on github.com. You might think permissions code is boring, but it's critical as well — bugs here could mean customer data is exposed, and in the case of source code you're not just talking about intellectual property, but secrets and vulnerabilities that could go on to endanger real people in the real world. A refactor like this could be daunting.
So how to approach? Well taking a note of everything the legacy code does is never a bad place to start, so let's pretend we've done that. Let's also pretend we've begun to refactor it and now we have a second piece of code that we think is equivalent to the original. Or, at least we thought we did until we found that other edge case.
What can be done to verify the correctness of our code? We've got tests, so that's good, but tests are not enough. Testing is "best effort", not a guarantee, and test coverage does not mean a codebase is well tested. Plus, bugs in code lead to bugs in data, and as Jesse puts it: "if you don’t know how your system works when it encounters this sort of bad data, it’s unlikely that you will design and test the new system to behave in the way that matches the legacy behavior."
The best way to know your code works as expected is to run it in production. Only production has the unique combination of throughput and data oddities needed to put your refactored code through its paces. But testing in production doesn't mean you should be shipping shoddy code to your users before it's ready. In fact it means quite the opposite — you should ghost ship your unproven code until you're confident it is ready. For all intents and purposes your legacy code is still the real implementation, but by running the new code in addition to the legacy we can collect real-world data on the correctness and performance characteristics without the risks of putting it live for real.
That idea is what spawned scientist for ruby, and the laboratory package means you can harness this simple but powerful idea in Python as well.
Laboratory
Laboratory has proven itself a valuable tool over the past couple of years in production at Marvel. From upgrading auth systems to changing important database queries and testing caching strategies, it's helped us to refactor, rethink, or improve performance a handful of times. Its value lies in its ability to give us a sense of confidence where there was none before.
By conducting experiments and verifying the results we can see if our new logic is ready to replace the legacy. If it isn't, we can dig into the experiment data to track down why, and because we send experiment metrics to statsd, we can correlate improvements in these metrics to changes in the codebase.
Conducting an experiment with laboratory is easy. First we create an experiment:
import laboratory
exp = laboratory.Experiment()
Then we tell the experiment what our control (legacy) and candidate (unproven) functions are:
exp.control(legacy_function)
exp.candidate(shiny_function)
And then we have it execute them and return the control value:
value = exp.conduct()
The code may be simple but the power is real. The experiment executed the candidate and the control functions in a random order, catching any exceptions in the candidate so it wouldn't affect the rest of the program. Then it compares the return values of the two functions and bundles this data up into a result along with some timing information it recorded earlier. It then publishes that to your metrics solution of choice (or a log).

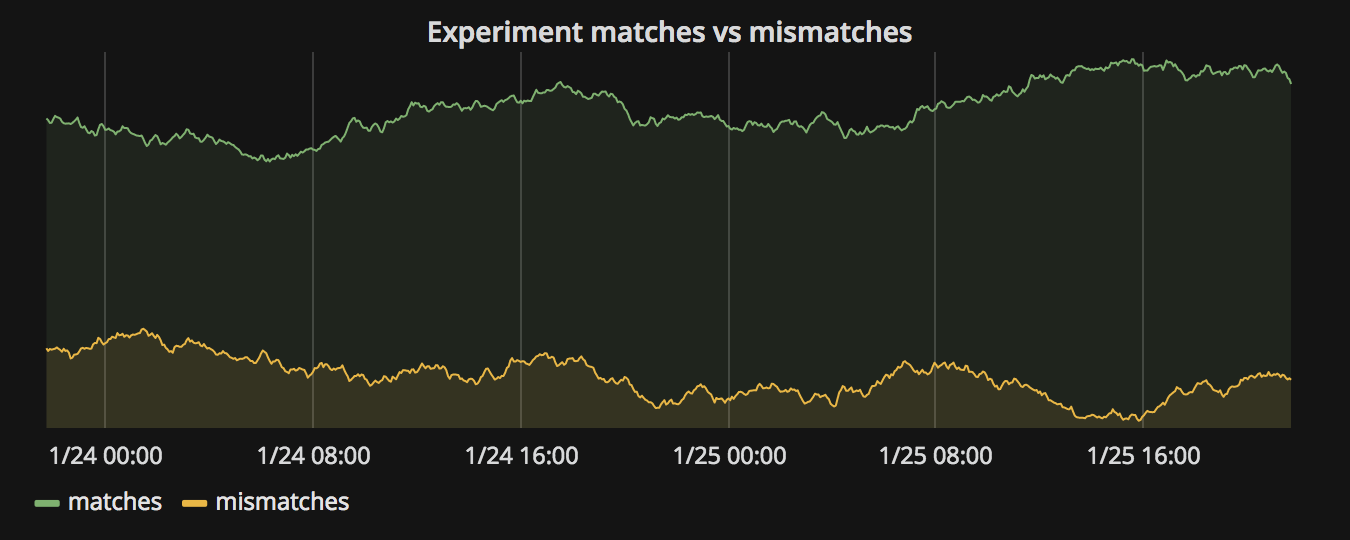
Publishing these results shows us in real time that the behaviour of our candidate and control blocks are divergent. Did we miss some functionality of the legacy code? Or perhaps the candidate has a bug? Data gremlins?
This is where that sense of confidence comes from. We may not have code that fully works yet, but we're far from wandering aimlessly. We know what we've got to do (fix the mismatches), we have the experiment context & mismatch data to help us do it, and we also have a metric by which to measure our progress (the number of mismatches). That's a feedback loop, and the tighter we can make it the better.
Careful, though
It should be noted that there are some caveats. This technique shouldn't be used if your code has side effects like database writes or other state changes. You could end up with more buggy data or a candidate that affects the execution of the control. You'll also take a performance hit by running your new code in addition to the old, so be mindful of that. You should ramp an experiment up slowly and keep an eye on your metrics.
Conclusion
Laboratory is all about sure-footed refactoring achieved through experimentation. You can prove your code in the real world without actually going live and the feedback loop this creates helps us converge on correctness more quickly.
Give it a go and see if it's a fit for your tool belt. https://github.com/joealcorn/laboratory